


SuperCLUE是什么?
SuperCLUE是中文通用大模型综合性评测基准,由国内CLUE学术社区于2023年5月推出,旨在全面评估中文大模型在语义理解、逻辑推理、代码生成等10项基础能力,以及涵盖数学、物理、社科等50+学科的专业能力。其特色在于针对中文特性任务(如成语、诗歌、字形)设立专项评测,并通过3700+客观题和匿名对战机制,动态追踪国内外主流模型(如GPT-4、文心一言、通义千问)的表现差异。
该平台提供三大核心评测体系:SuperCLUE-OPEN(多轮开放式问答)、SuperCLUE-OPT(客观题闭卷测试)和“琅琊榜”匿名对战,每月更新榜单并支持开发者横向对比模型效果。作为中文领域权威测评社区,其评测结果被学界和产业界广泛引用,例如商汤“日日新5.0”和百度文心大模型均通过SuperCLUE验证技术突破,推动中文NLP技术生态的迭代。
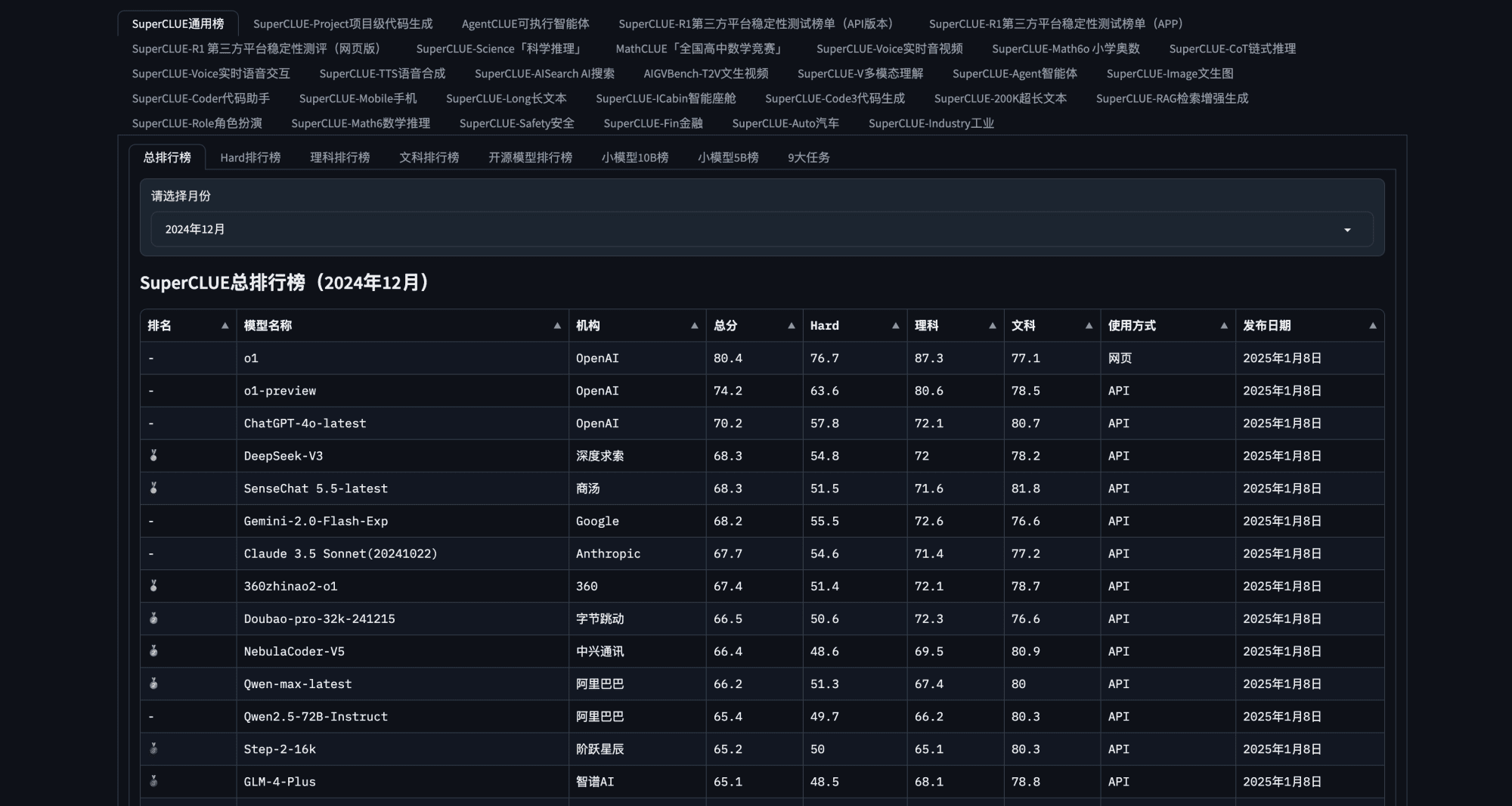
SuperCLUE有哪些排行榜?
- 总排行榜:综合评估模型在基础能力、中文特性、专业能力等维度的整体表现,定期更新国内外主流模型排名。
- 基础能力排行榜:细分10项子能力:语义理解、对话、逻辑推理、角色扮演、代码、生成与创作等,考察通用场景下的核心能力。
- 中文特性能力排行榜:聚焦中文特有任务:如成语解析、诗歌创作、文学理解、字形识别等10项能力,凸显本土化优势。
- 专业能力排行榜:覆盖学术领域:包括数学、物理、地理、社会科学等50+学科考试题目,评估模型的专业知识深度。
- OPT客观题排行榜:基于3700+道选择题(闭卷考试形式),通过自动化测评考察模型在基础、中文、专业三大能力的客观表现。
- OPEN多轮开放问题排行榜:评估多轮对话、开放性问题的处理能力,侧重生成质量和逻辑连贯性。
- AIAgent榜单:业界首个AI智能体专项榜单,重点评测工具使用、任务规划能力,反映模型作为人类助手的实用性。
- 开源模型排行榜:单独评估开源模型的竞争力,如Baichuan-13B等模型曾登顶国内开源榜首。
- 安全性与伦理榜单:考察系统安全、指令攻击防御等维度,评估模型的安全风险控制能力。
- 琅琊榜(匿名对战平台):用户投票生成的动态排名,通过实战对比模型在匿名环境下的实际表现。
Super适合什么人用?
- 学术研究者与评测机构:需要客观评估中文大模型性能的科研团队或第三方评测机构,可通过SuperCLUE的多维度测评(基础能力、专业能力、中文特性能力)获取模型对比数据,支持学术论文或技术报告撰写。
- AI开发者与算法工程师:需优化大模型表现的技术人员,可利用SuperCLUE的自动化测试工具分析模型短板(如代码生成、逻辑推理等),针对性调整训练策略或架构设计。
- 企业技术决策者与产品团队:需选型商用大模型的企业,可参考SuperCLUE榜单(如月度更新排名)对比国内外模型优劣势,结合业务场景(如长文本处理、安全合规)选择适配方案。
- 教育机构与考试评测组织:关注模型在学科考试(数学、物理等)或中文文化任务(诗歌生成、成语理解)表现的单位,可通过专业能力测试模块评估模型的教育辅助潜力。
- 政策制定者与行业监管部门:需掌握中文AI技术发展水平的政府部门,可借助SuperCLUE的行业趋势分析(如国内模型与国际差距)制定技术标准或产业扶持政策。
- 投资者与市场分析师:需评估AI公司技术竞争力的机构,可通过模型排名(如商汤「日日新5.0」领跑文科能力)判断企业研发实力与商业化价值。
- 普通用户与技术爱好者:想了解大模型实际能力的个人,可参考SuperCLUE开放榜单(如GPT-4与星火认知对比)选择适合日常使用的AI工具。
SuperCLUE的结果靠谱吗?
此外,其测试方式未适配生成式大模型特性,例如用选择题评估生成能力导致结果与实际体验偏差较大。这些问题削弱了其作为通用基准的可信度,部分业内人士认为其初期更接近营销工具而非科学评测。然而,SuperCLUE在后续迭代中逐步提升专业性。
2024年版本通过引入多维度测评(理科、文科、Hard任务)、开放主观题评测及自动化技术,增强了科学性。其覆盖金融、医疗等垂类场景的细分榜单,以及商汤、腾讯混元等头部厂商的参与和认可,反映出行业对其权威性的部分接纳。
尽管仍需警惕潜在利益关联,但其方法论改进和多元化的测评体系已推动其成为国内大模型能力对比的重要参考。
数据统计
暂无评论...
相关网站
















小众AI工具库(www.xiaozhongai.com),精选国内外免费AI工具,涵盖AI绘画、AI写作、AI视频制作、AI聊天对话等高效AI神器!助你解锁AI生产力,探索最强AI工具合集!立即访问,发现更多AI黑科技!

